State of AI: Эмпирическое исследование 100 триллионов токенов
Глубокий анализ рынка ИИ на основе данных OpenRouter: более 50% трафика приходится на рассуждающие модели, китайские Open Source решения захватывают кодинг, а феномен «Хрустальной туфельки» определяет удержание пользователей.
State of AI: Эмпирическое исследование 100 триллионов токенов с OpenRouter
Авторы: Malika Aubakirova*, Alex Atallah, Chris Clark, Justin Summerville, and Anjney Midha (OpenRouter Inc. & a16z) Дата: Декабрь 2025
Аннотация
Прошедший год стал поворотным моментом в эволюции и реальном использовании больших языковых моделей (LLM). С выпуском первой широко принятой модели рассуждения, o1, 5 декабря 2024 года, область сместилась от однопроходной генерации паттернов к многоэтапному инференсу с обдумыванием, что ускорило развертывание, экспериментирование и появление новых классов приложений. Поскольку этот сдвиг происходил быстрыми темпами, наше эмпирическое понимание того, как эти модели фактически используются на практике, отставало.
В данной работе мы используем платформу OpenRouter, которая является провайдером ИИ-инференса для широкого спектра LLM, чтобы проанализировать более 100 триллионов токенов реальных взаимодействий с LLM в различных задачах, географических регионах и во времени. В нашем эмпирическом исследовании мы наблюдаем существенное внедрение моделей с открытыми весами, огромную популярность категорий креативного ролевого отыгрыша и помощи в написании кода, а также рост агентского инференса. Кроме того, наш анализ удержания выявляет основополагающие когорты: ранних пользователей, чья вовлеченность сохраняется гораздо дольше, чем у более поздних когорт. Мы называем это явление эффектом «Хрустальной туфельки».
1. Введение
Всего год назад ландшафт больших языковых моделей выглядел фундаментально иначе. До конца 2024 года в современных системах доминировали однопроходные авторегрессионные предикторы, оптимизированные для продолжения текстовых последовательностей. Эта парадигма эволюционировала 5 декабря 2024 года, когда OpenAI выпустила первую полную версию своей модели рассуждения o1.
Позиция OpenRouter предоставляет уникальное окно в детализированные паттерны использования. Мы анализируем:
- Открытые против закрытых моделей: Баланс сил между проприетарными гигантами и Open Source.
- Агентский инференс: Сдвиг к многоэтапным рабочим процессам.
- География: Как Азия становится ключевым потребителем ИИ.
- Эффективная стоимость: Экономика использования моделей.
- Удержание: Почему пользователи остаются с конкретными моделями.
2. Данные и Методология
Наш анализ основан на метаданных, собранных с платформы OpenRouter. Набор данных состоит из анонимизированных метаданных на уровне запросов для миллиардов пар «промпт-завершение» от глобальной пользовательской базы. Мы используем классификатор GoogleTagClassifier для категоризации контента (Programming, Roleplay, Translation и т.д.).
3. Открытые (Open Source) против Закрытых (Proprietary) моделей
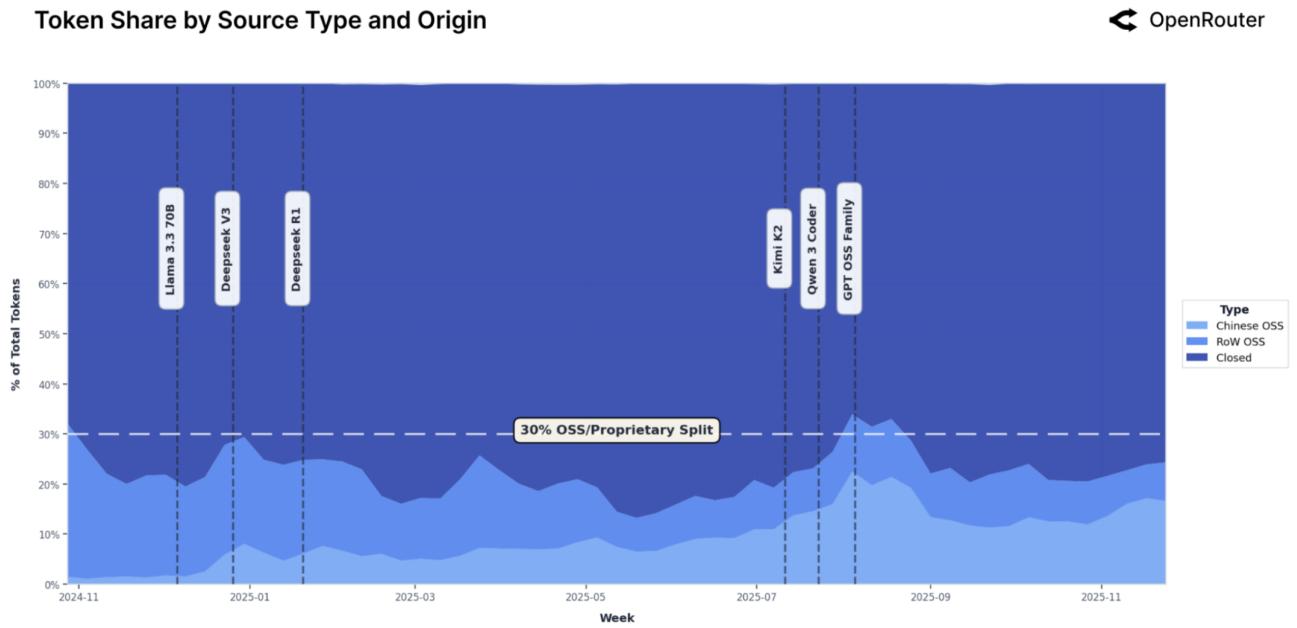 Рисунок 1: Еженедельная доля общего объема токенов по типу источника. Светло-голубые оттенки — Open Source, темно-синий — проприетарные.
Рисунок 1: Еженедельная доля общего объема токенов по типу источника. Светло-голубые оттенки — Open Source, темно-синий — проприетарные.
Хотя проприетарные модели (OpenAI, Anthropic) по-прежнему обслуживают большинство токенов, модели OSS неуклонно росли, достигнув примерно одной трети использования к концу 2025 года. Значительная часть этого роста пришлась на модели китайской разработки (DeepSeek, Qwen), которые достигли почти 30% от общего использования.
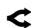
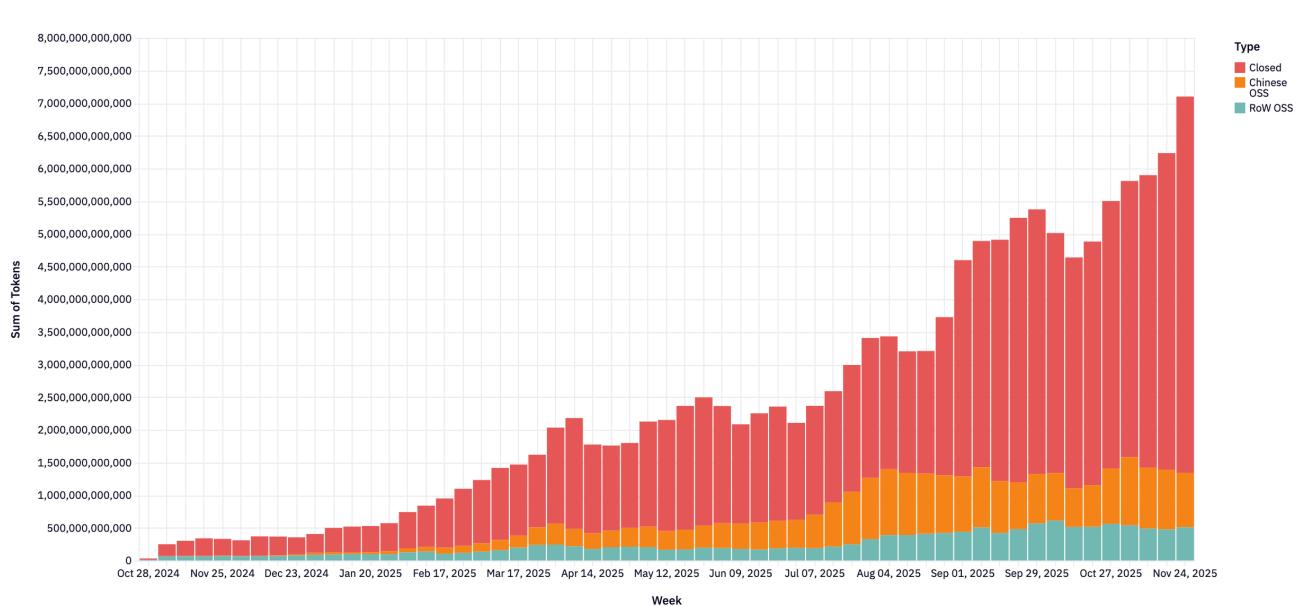 Рисунок 2: Еженедельный объем токенов по типу модели.
Рисунок 2: Еженедельный объем токенов по типу модели.
3.1 Ключевые игроки Open Source
Ландшафт OSS-моделей значительно изменился. Если раньше доминировал DeepSeek, то теперь рынок стал более плюралистичным.
Таблица 1: Топ авторов моделей по объему токенов (Ноябрь 2024 – Ноябрь 2025)
| Автор модели | Всего токенов (триллионы) |
|---|---|
| DeepSeek | 14.37 |
| Qwen | 5.59 |
| Meta LLaMA | 3.96 |
| Mistral AI | 2.92 |
| OpenAI (OSS) | 1.65 |
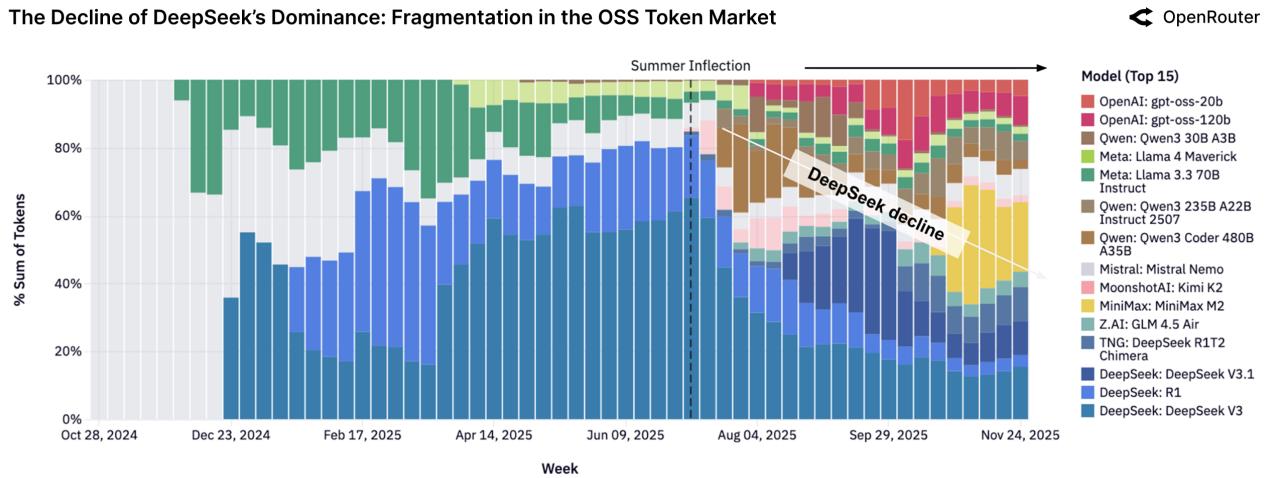 Рисунок 3: Доли рынка топ-15 OSS-моделей с течением времени.
Рисунок 3: Доли рынка топ-15 OSS-моделей с течением времени.
3.2 Размер имеет значение: “Medium is the New Small”
Эра доминирования малых моделей (<15B) прошла. Рынок смещается к моделям среднего размера (15-70B), таким как Qwen2.5 32B и Mistral Small 3, которые обеспечивают идеальный баланс цены и качества.

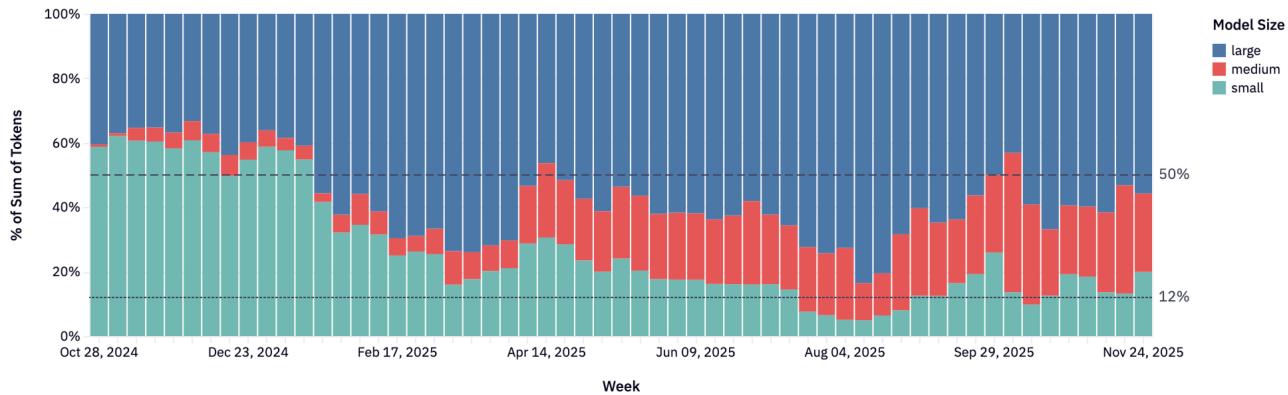 Рисунок 4: Размер OSS-модели против использования.
Рисунок 4: Размер OSS-модели против использования.
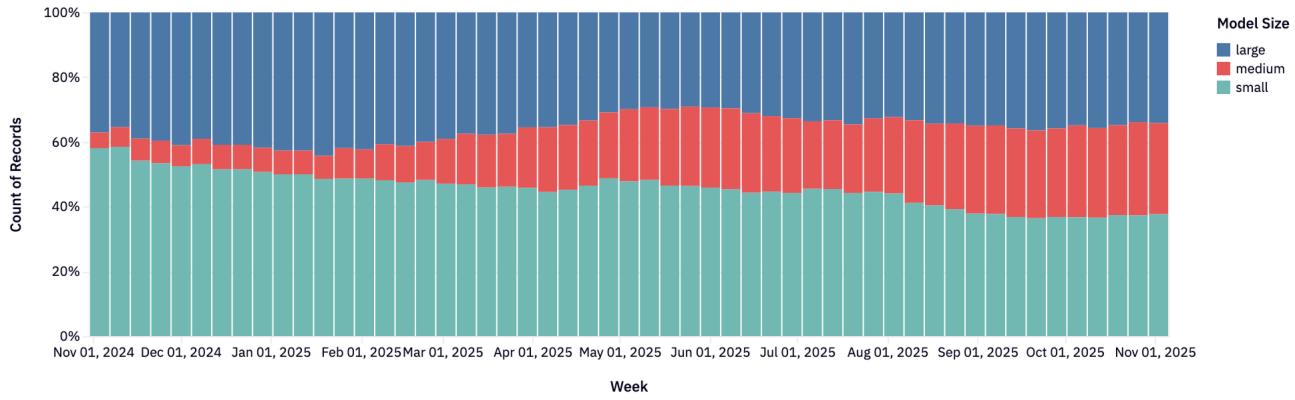 Рисунок 5: Количество OSS-моделей по размеру.
Рисунок 5: Количество OSS-моделей по размеру.
3.3 Для чего используют Open Source?
Две главные категории: Roleplay (Ролевой отыгрыш) и Programming (Программирование).
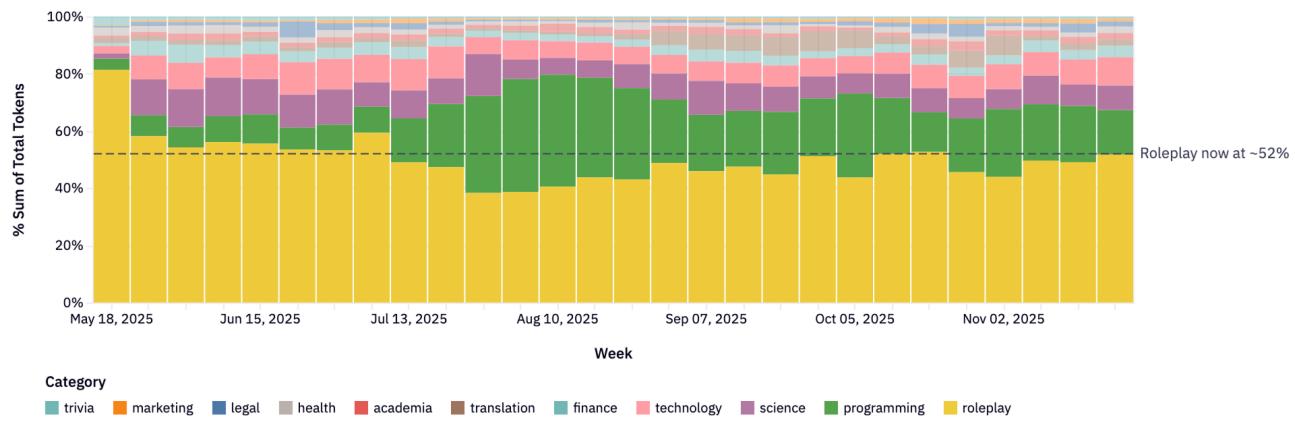 Рисунок 6: Распределение использования моделей OSS по категориям.
Рисунок 6: Распределение использования моделей OSS по категориям.
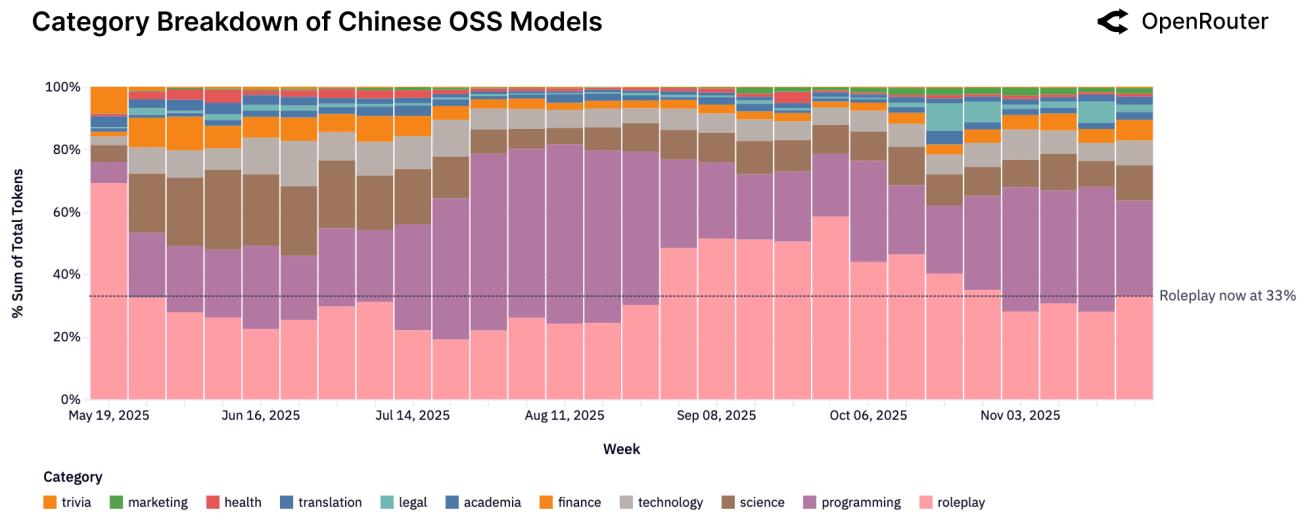 Рисунок 7: Категории использования китайских OSS-моделей. Программирование и технологии составляют 39%.
Рисунок 7: Категории использования китайских OSS-моделей. Программирование и технологии составляют 39%.
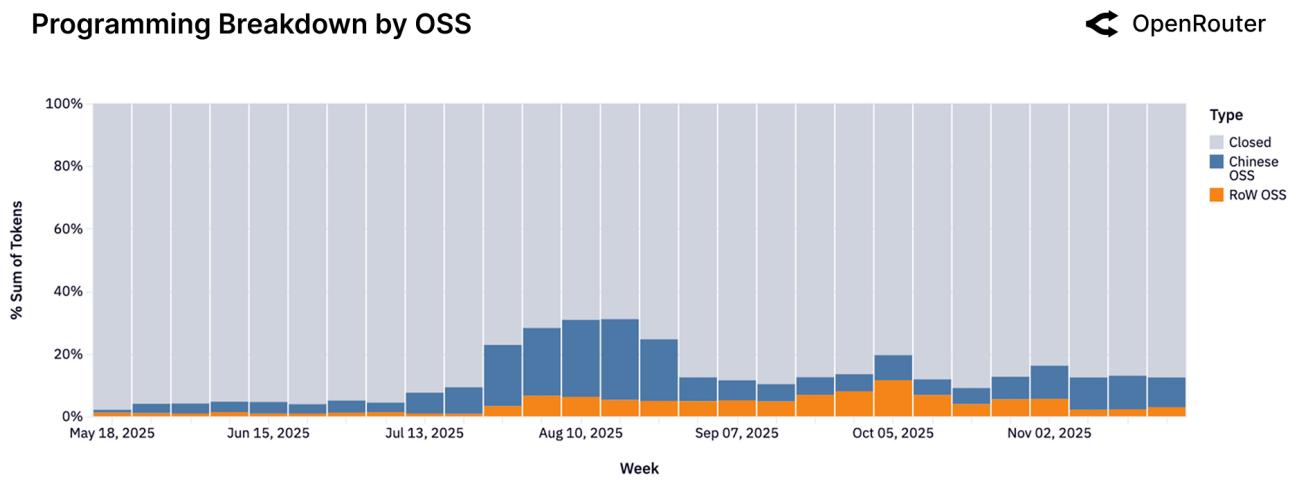 Рисунок 8: Запросы по программированию по источнику модели.
Рисунок 8: Запросы по программированию по источнику модели.
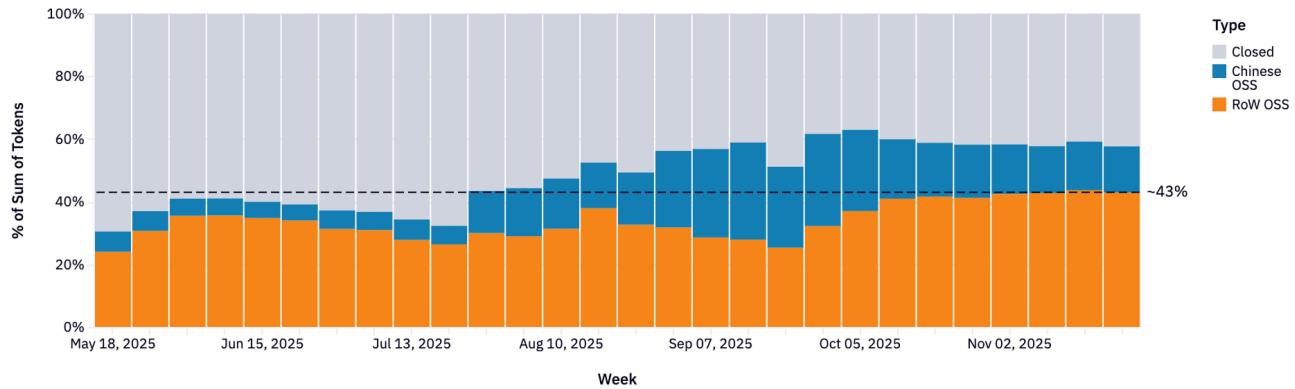 Рисунок 9: Запросы по ролевому отыгрышу.
Рисунок 9: Запросы по ролевому отыгрышу.
4. Расцвет Агентного Инференса (Agentic Inference)
Происходит фундаментальный сдвиг от одношаговой генерации к многоэтапным рабочим процессам с использованием инструментов и рассуждений.
4.1 Модели рассуждения занимают 50% трафика
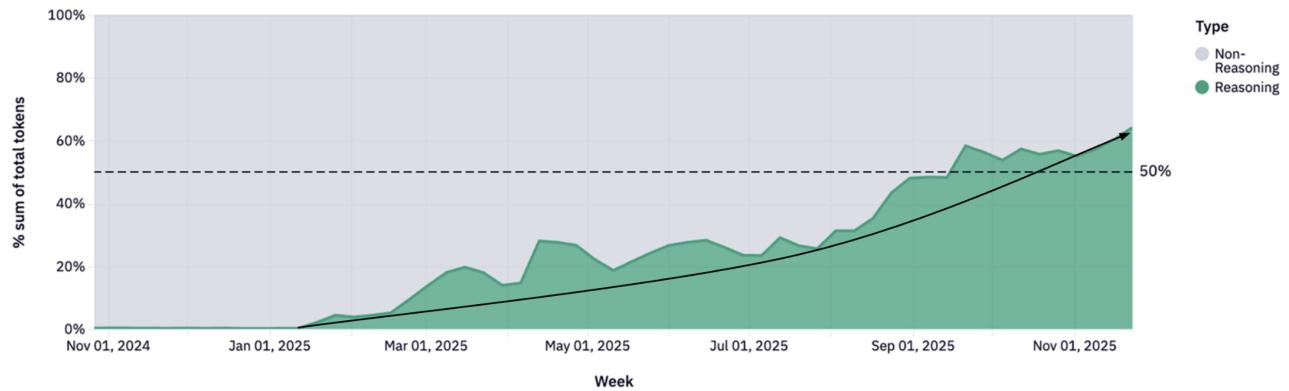 Рисунок 10: Доля токенов через модели рассуждения.
Рисунок 10: Доля токенов через модели рассуждения.

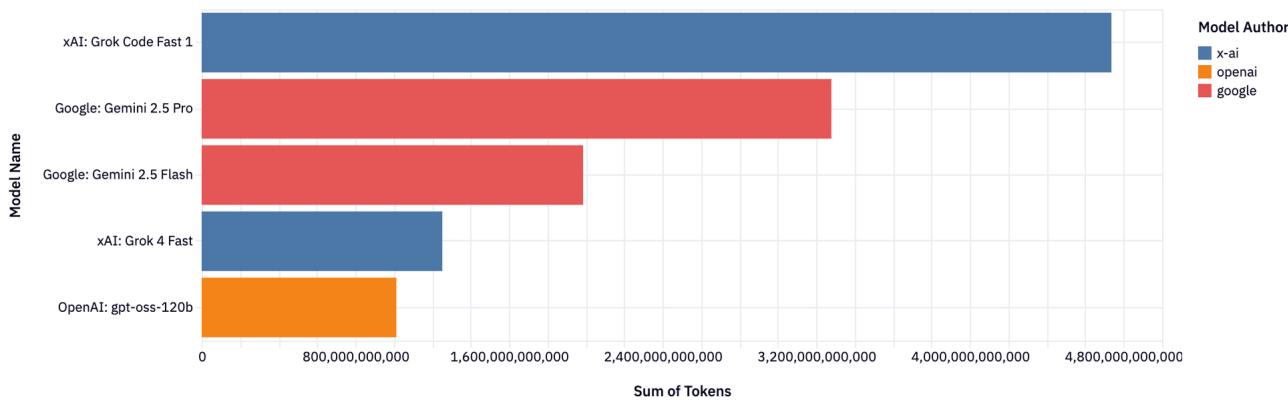 Рисунок 11: Топ моделей рассуждения. Лидирует Grok Code Fast 1.
Рисунок 11: Топ моделей рассуждения. Лидирует Grok Code Fast 1.
4.2 Рост использования инструментов (Tool-Calling)
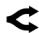
 Рисунок 12: Доля токенов с успешным вызовом инструментов.
Рисунок 12: Доля токенов с успешным вызовом инструментов.
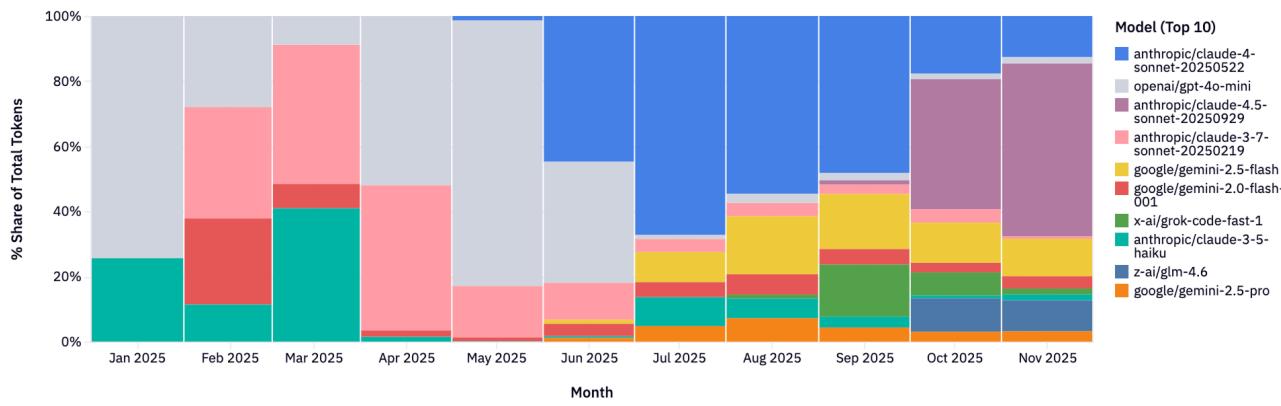 Рисунок 13: Топ моделей по использованию инструментов.
Рисунок 13: Топ моделей по использованию инструментов.
4.3 Анатомия запросов: Рост контекста в 4 раза
Средняя длина промпта выросла с 1.5k до >6k токенов. Это означает, что пользователи загружают в модели целые документы и кодовые базы.
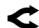
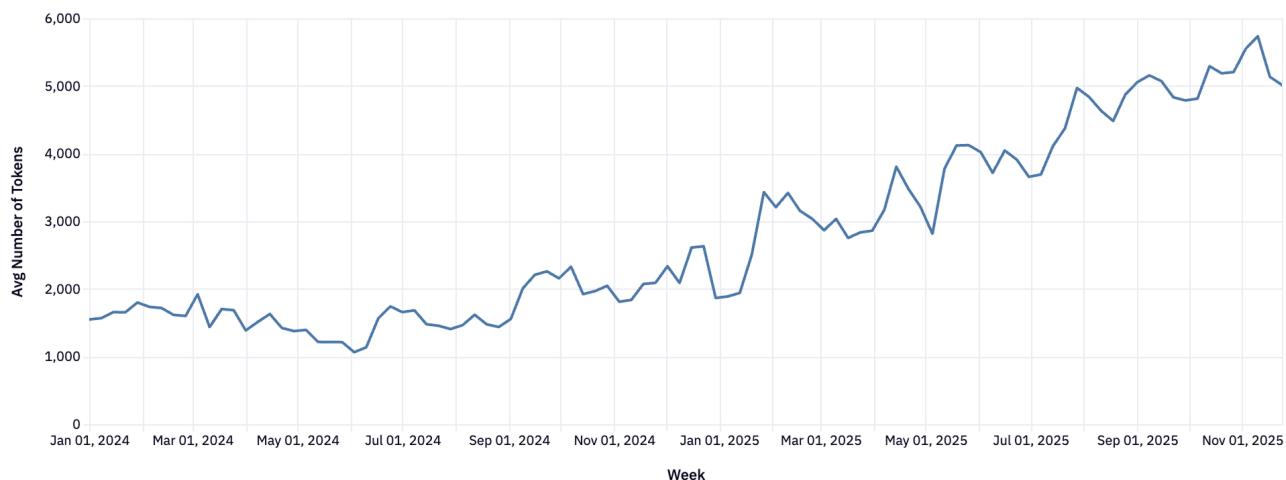 Рисунок 14: Рост длины промпта.
Рисунок 14: Рост длины промпта.
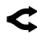
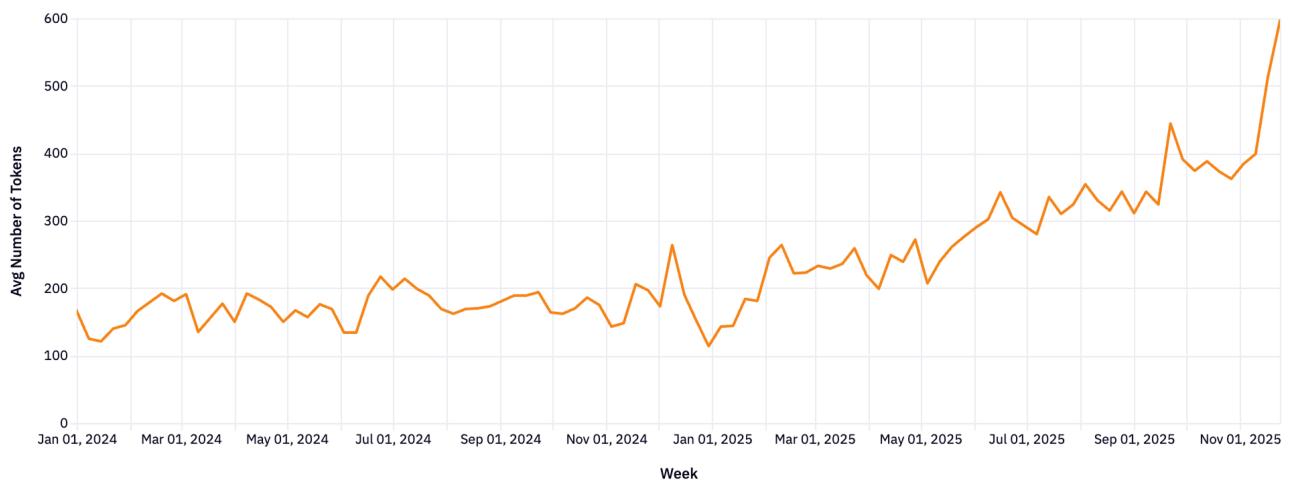 Рисунок 15: Рост длины ответа (completion tokens) почти в 3 раза.
Рисунок 15: Рост длины ответа (completion tokens) почти в 3 раза.
Программирование — основной драйвер этого роста.

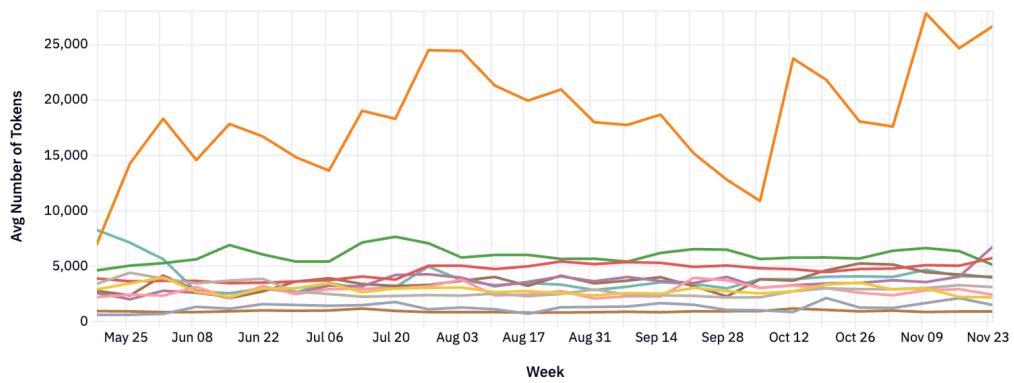 Рисунок 16: Программирование требует самых длинных контекстов.
Рисунок 16: Программирование требует самых длинных контекстов.
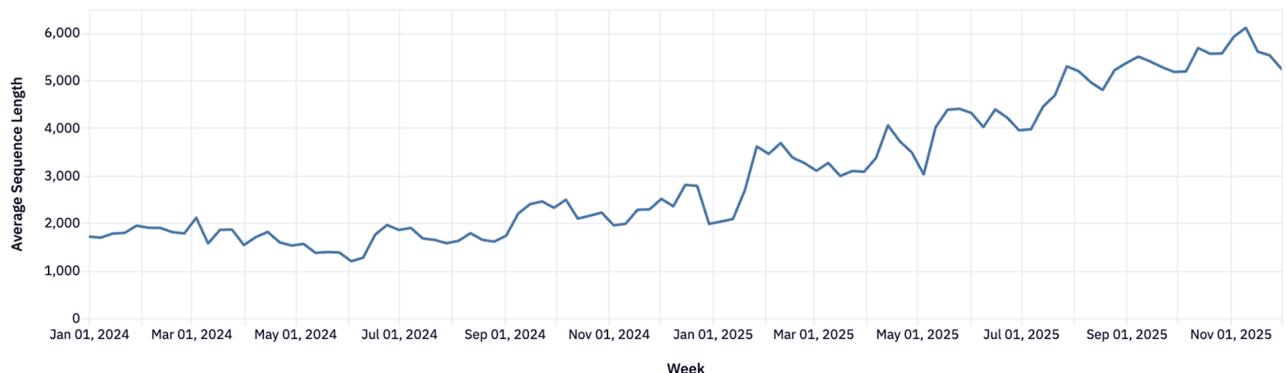 Рисунок 17: Средняя длина последовательности.
Рисунок 17: Средняя длина последовательности.
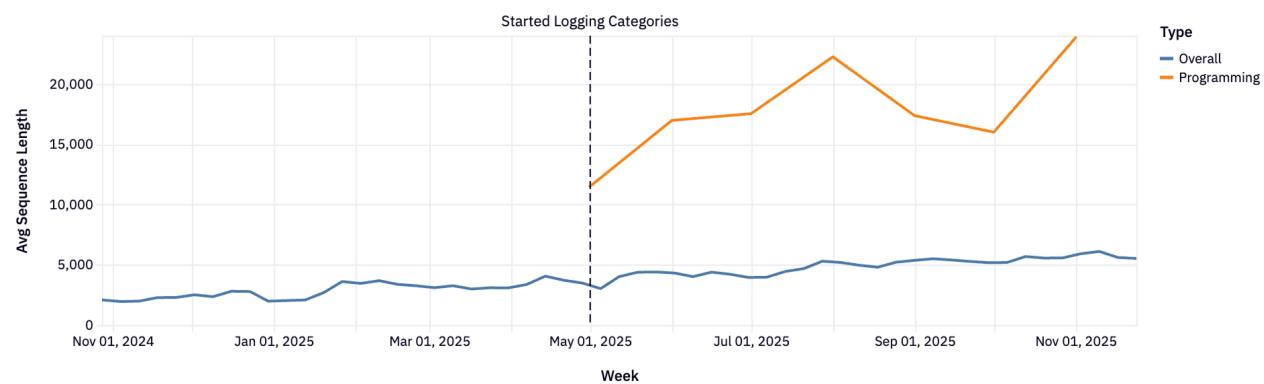 Рисунок 18: Сравнение длины последовательности в программировании и общих задачах.
Рисунок 18: Сравнение длины последовательности в программировании и общих задачах.
5. Категории: Как люди используют LLM?
5.1 Доминирующие категории
Программирование стало доминирующей категорией, превысив 50% трафика к концу 2025 года.
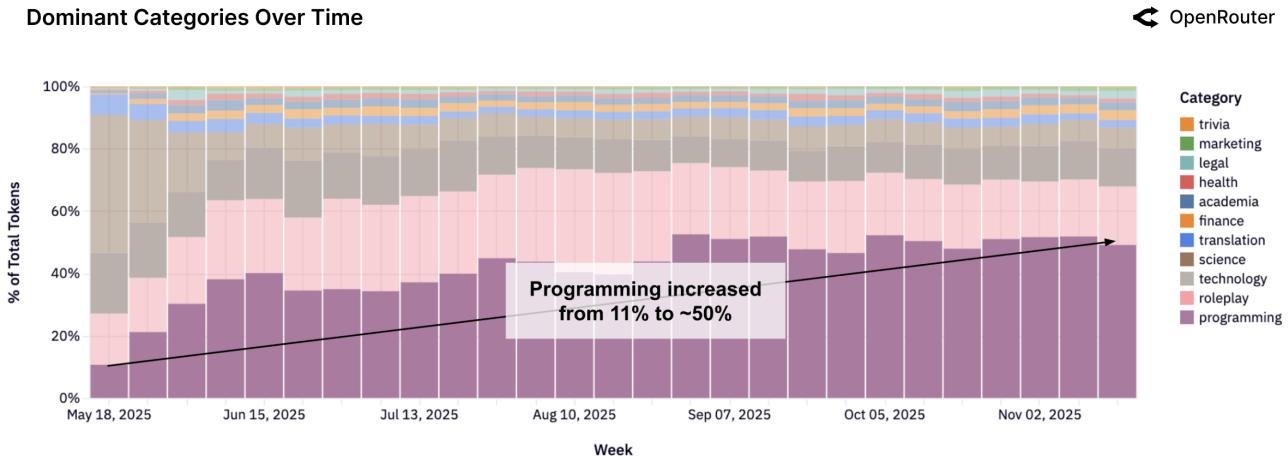 Рисунок 19: Доля запросов по программированию.
Рисунок 19: Доля запросов по программированию.
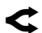
 Рисунок 20: Доля рынка провайдеров в программировании. Anthropic лидирует, но теряет долю.
Рисунок 20: Доля рынка провайдеров в программировании. Anthropic лидирует, но теряет долю.
5.2 Состав тегов
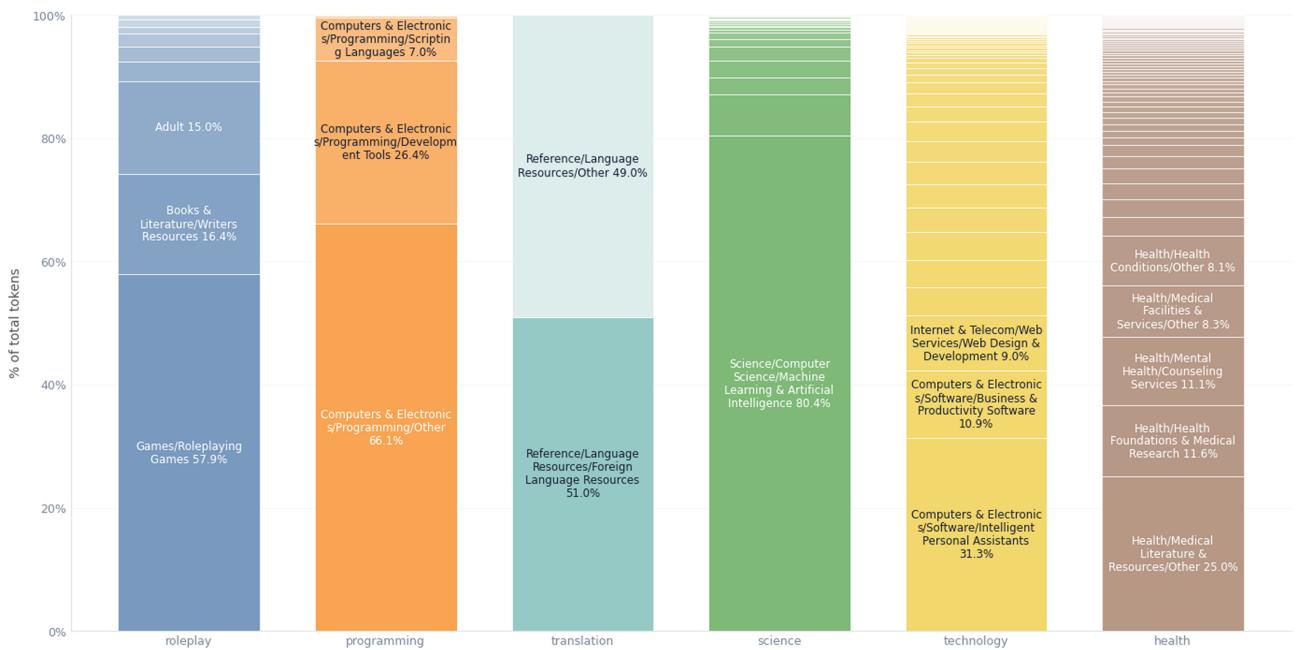
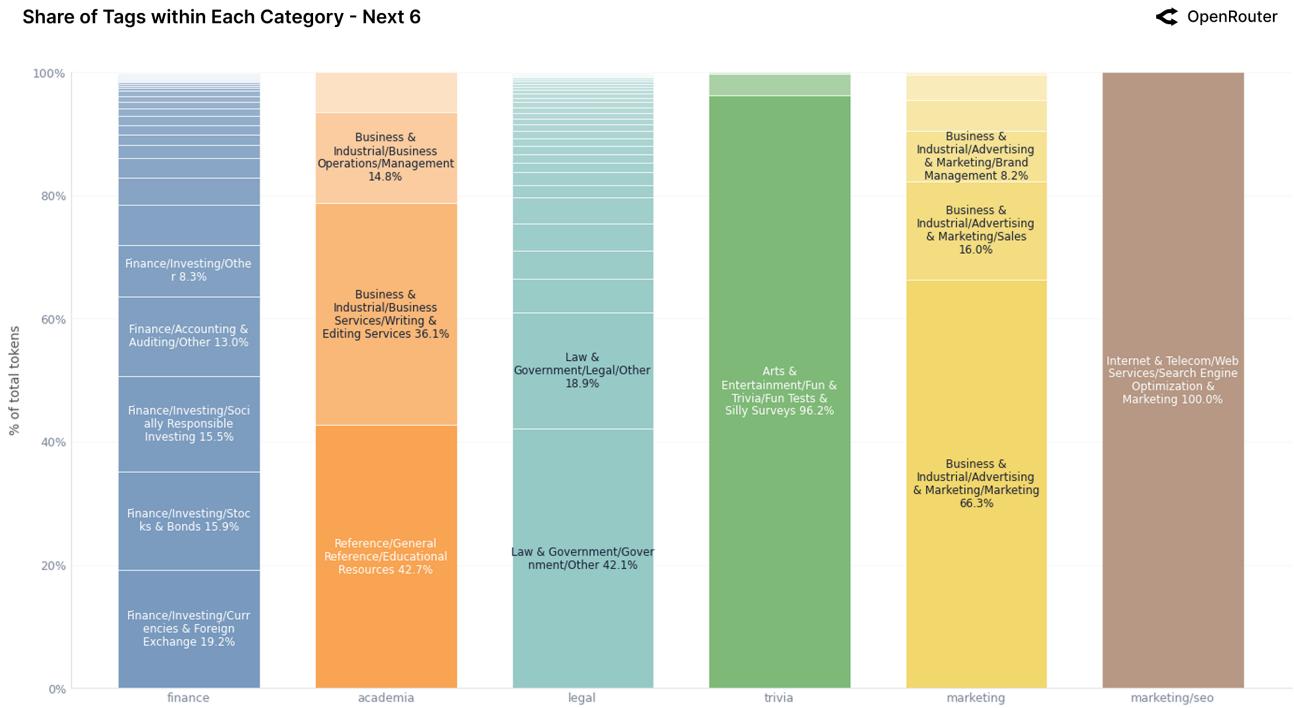 Рисунок 21: Детализация подкатегорий (Programming, Roleplay, Technology и др.).
Рисунок 21: Детализация подкатегорий (Programming, Roleplay, Technology и др.).
5.3 Инсайты по провайдерам
Каждый провайдер имеет свою нишу:
- Anthropic: Программирование и технологии (>80%).
- Google: Широкий спектр (юриспруденция, наука, технологии).
- xAI: Сильный фокус на программировании.
- DeepSeek: Доминирование в Roleplay и чате.
- Qwen: Технический фокус (40-60% кодинг).
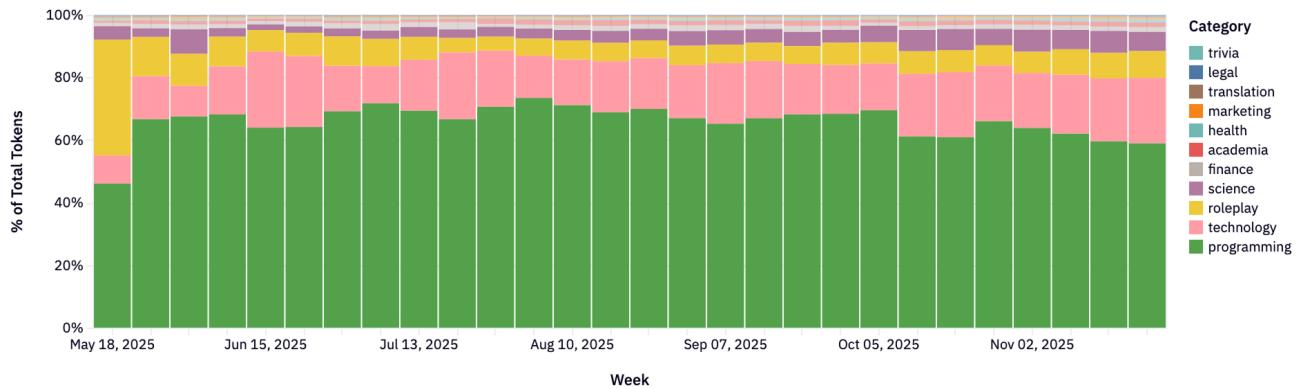
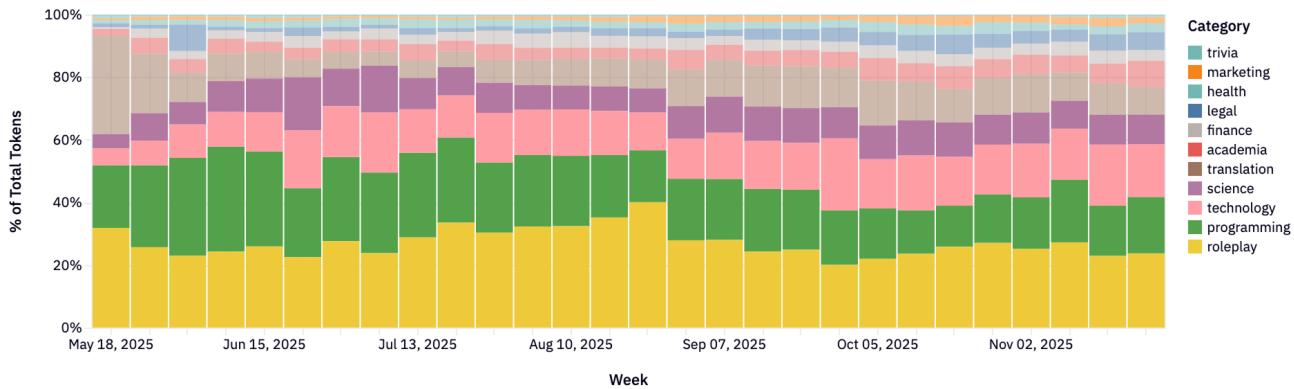
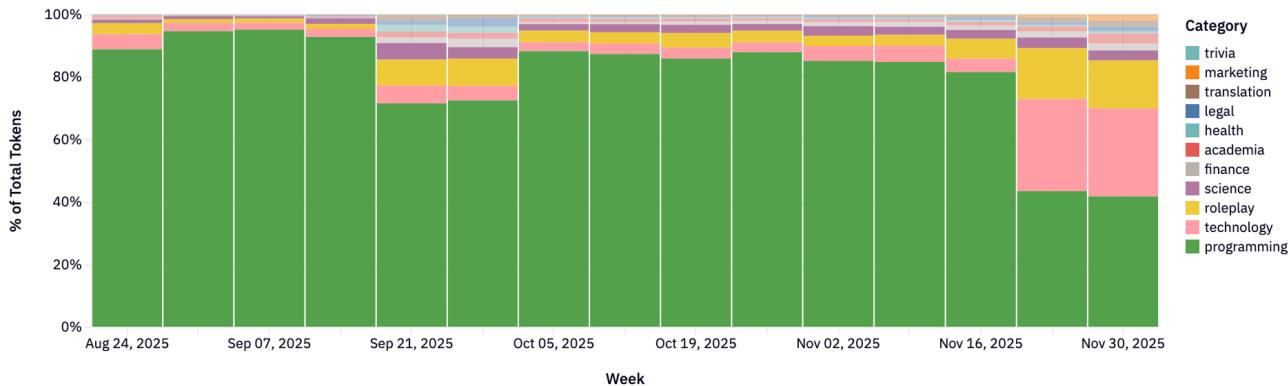
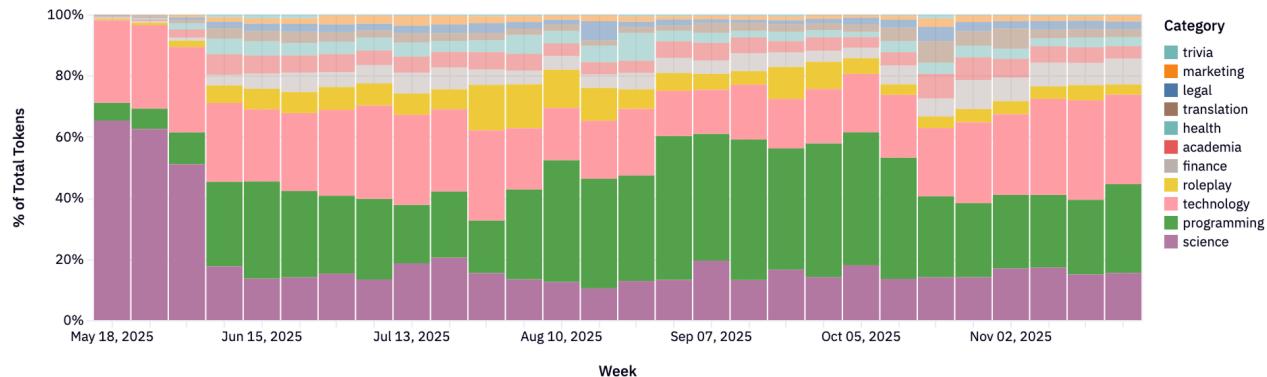
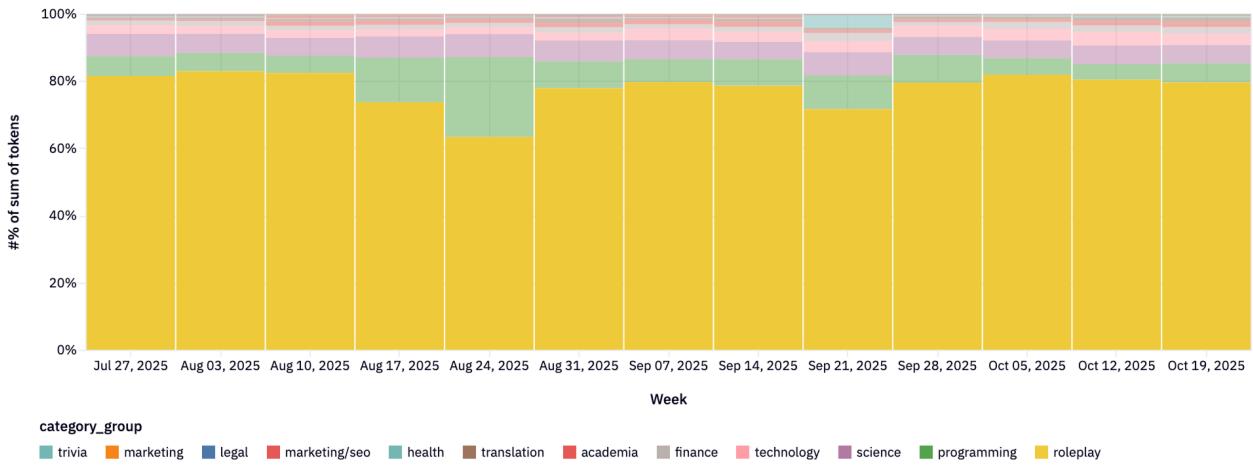
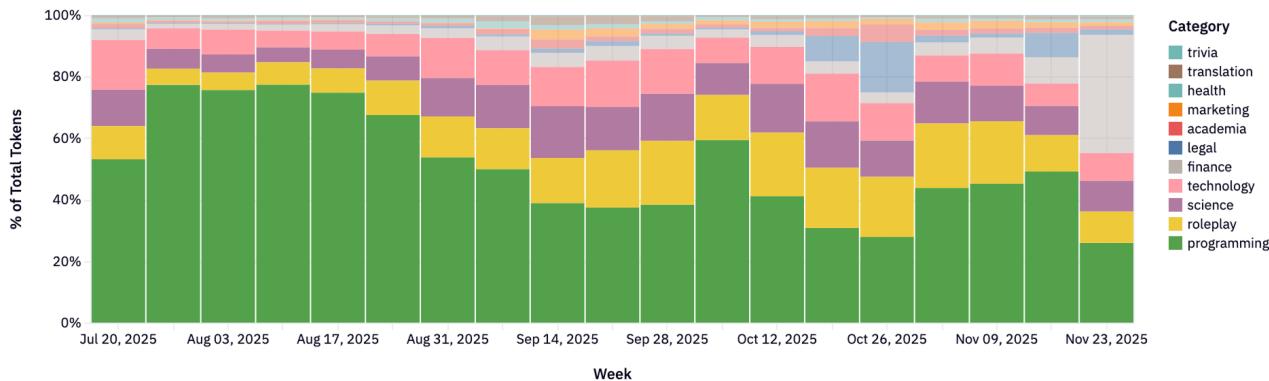 Рисунки 22-23: Распределение категорий по провайдерам.
Рисунки 22-23: Распределение категорий по провайдерам.
6. География: Азия как новый центр силы
Азия удвоила свою долю в потреблении ИИ, достигнув 31% глобальных расходов.
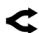
 Рисунок 24: Расходы по регионам.
Рисунок 24: Расходы по регионам.
Таблица 2: Языки запросов
| Язык | Доля (%) |
|---|---|
| Английский | 82.87 |
| Китайский (упр.) | 4.95 |
| Русский | 2.47 |
7. Удержание пользователей: Эффект «Хрустальной туфельки»
Мы обнаружили феномен «Хрустальной туфельки»: пользователи остаются с той моделью, которая первой идеально решила их сложную задачу.
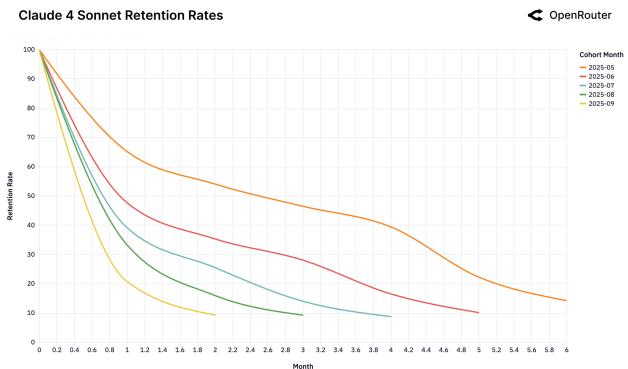
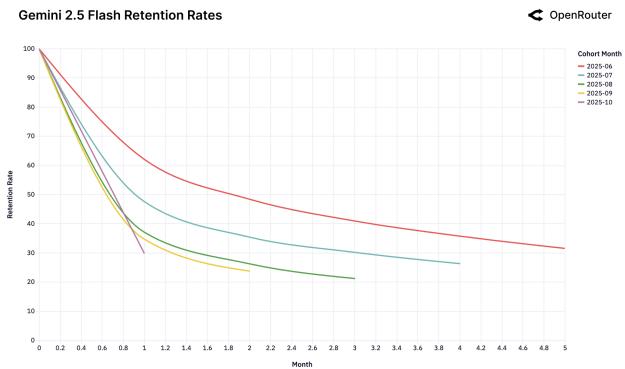
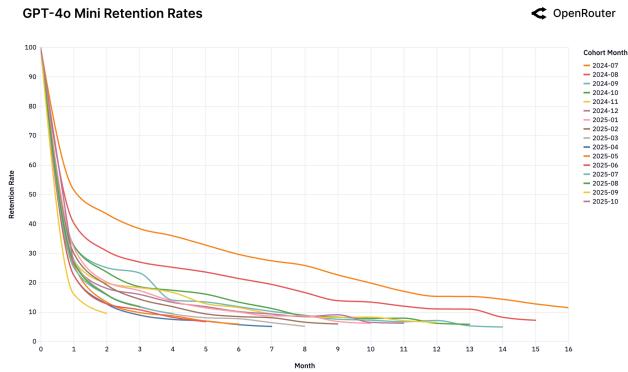
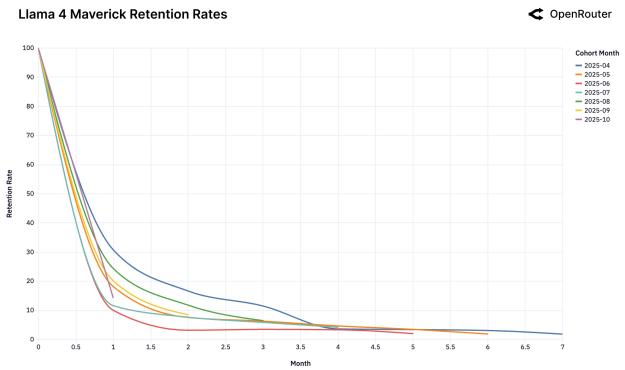
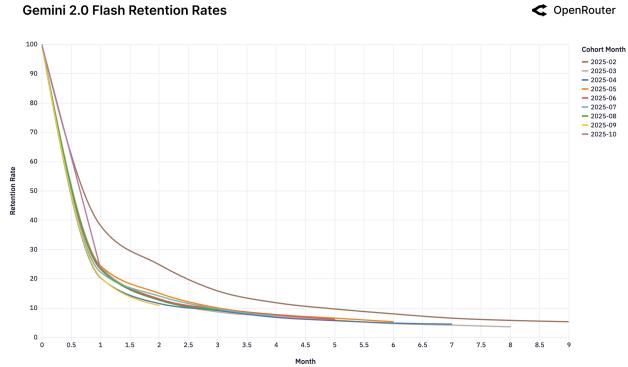
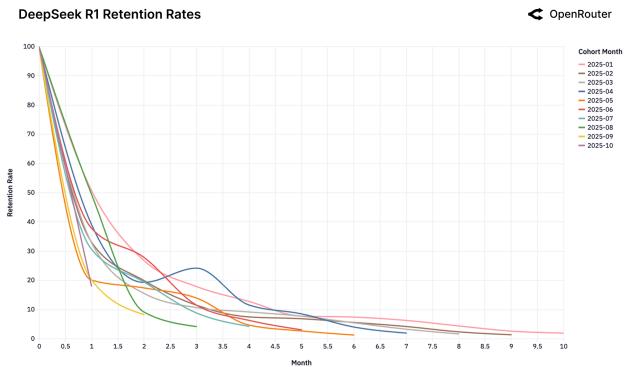
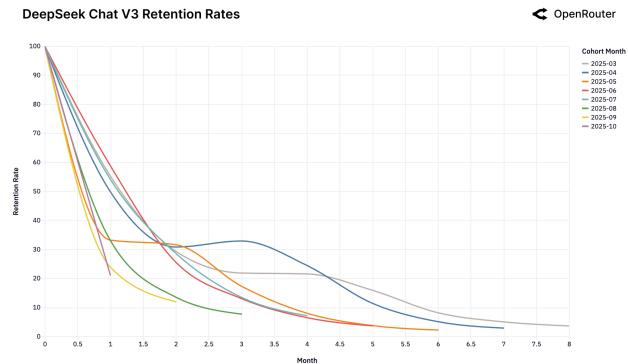 Рисунок 25: Когорты удержания для различных моделей.
Рисунок 25: Когорты удержания для различных моделей.
8. Динамика стоимости и использования
Рынок четко сегментирован:
- Премиум (Tech, Science): Высокая цена, высокое использование.
- Масс-маркет (Programming, Roleplay): Низкая цена, огромное использование.
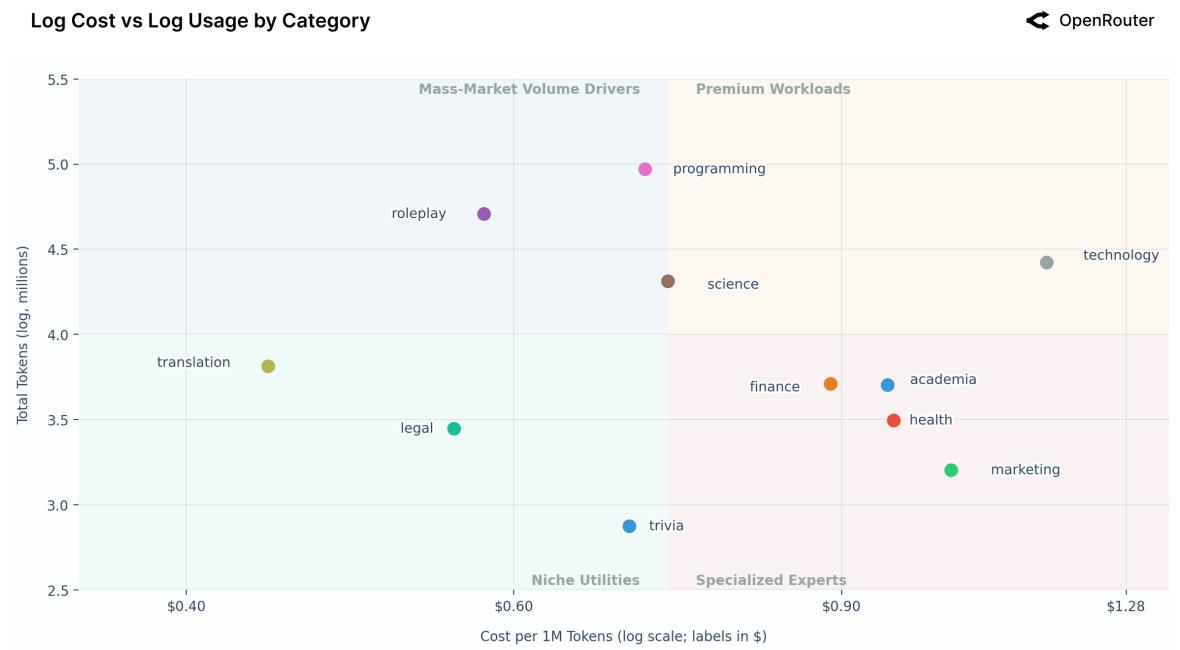 Рисунок 26: Карта рынка (Логарифм стоимости vs Логарифм использования).
Рисунок 26: Карта рынка (Логарифм стоимости vs Логарифм использования).